Présentation de l'API 'Resources'Ce document présente l'API 'Resources' : objectifs, architecture, détails d'implémentation, exemples et tests. Vous y trouverez aussi des liens et explications pour la javadoc, les sources et les binaires.  1.0. Pour commencer ... 1.1. Objectifs 1.2. Statut 1.3. Ce document 2.0. Pour rentrer dans le vif du sujet ... 2.1. Getting started 2.1.1. Prérequis et téléchargements 2.1.2. Installation et tests 2.1.3. "Hello Resources World" 2.2. Architecture 2.2.1. Vue d'ensemble 2.2.2. Les ressources 2.2.3. Les readers 2.2.4. Les writers 2.2.5. Les autres 3.0. Pour aller plus loin ... 3.1. Téléchargements, liens et docs 3.2. Conclusion 1.0. Pour commencer ...1.1. ObjectifsCette API a pour objectif de permettre l'accès à nos ressources (FAQs, pages de codes sources, critiques de livres, etc.) à partir des outils (ie. EDI) utilisés par nos membres. Les principaux cas d'utilisation de cette API seraient dans des plugins/modules pour Eclipse, Netbeans, etc.
 . Voici quelques cas d'utilisation intéressants : . Voici quelques cas d'utilisation intéressants :
En passant, ca peut aussi nous permettre d'offrir d'autres types de services intéressants.
Par exemple, la plupart des EDI actuels proposent des templates/codes clips/snippets, or grâce nos FAQs et codes sources on a de quoi remplir des bouquins entiers de petits morceaux de code réutilisables.
On peut très bien imaginer regrouper ce qu'il y a de vraiment réutilisable dans une ressource et rendre le tout accessible grâce aux plugins qu'on aura créés.
Voila, voila, pour les objectifs, passons au statut actuel de "la chose". 1.2. Statut Pour synthétiser : l'API est écrite, elle est "documentée" (notez les guillemets), un jeu de tests unitaires a été écrit et deux prototypes créés (un module Netbeans et une application Eclipse RCP). Le module Netbeans Vous pour voir une démonstration wink de ce module à cete adresse : http://vedaer.developpez.com/netbeans/nbm.htm. Par contre, disons que j'ai "perdu" les sources. Si ca peut me faire pardonner, et pour la petite histoire, ce n'était que le premier test que j'avais fait pour l'API (depuis, elle a été réecrite pour la mettre au "propre"). De plus, au final, le module, dans l'état ou il était, n'était constitué que de deux ou trois Tree/TableModel et quelques composants SwingX qui se battaient en duel. Donc, si je peux me permettre, ce n'est pas une très grosse perte. Au final, il est préférable de repartir de zéro avec la version actuelle de l'API pour faire un joli module Netbeans :)  L'application Eclipse RCP En dehors des tests unitaires, pour essayer l'API, j'ai écrit une petite application Eclipse RCP que je pense adapter par la suite en plugin pour l'EDI du même nom
 .
.Vous pouvez voir une petite démo (vidéo de 43 Mo !) en cliquant sur la petite image ci contre. La qualité de la vidéo n'est pas tip top, mais je pense pouvoir vous fournir de quoi tester directement très bientôt. Vous pourrez y voir un exemple de "répertoire de ressources" (FAQs, codes sources, livres, blogs, ...) et quelques fonctionnalités qu'on peut offrir avec cette API : navigation, recherche, contacts des auteurs, bookmarks, ... Passons à la suite J'espère que vous voyez maintenant un peu mieux le statut actuel du 'truc' et les possibilités que ca offre.
Pour la suite, on ne parlera plus de module, de plugin ou d'EDI, mais simplement de l'API et de son utilisation. Donc, si vous n'avez pas l'intention de participer au dév. de l'API et des outils cités ci-dessus, la suite aura un peu moins d'interêt puisque ca va se résumer à quelques diagrammes de classe, quelques explications fumeuses et à deux ou trois morceaux de code ;) 1.3. Ce documentPour commencer, je vais vous guider pour la création d'un "Hello world" (téléchargement, installation, compilation). Ca vous donnera une idée plus claire de ce que j'entends par ressource, répertoire de ressources, etc. Dans la seconde partie, je vais rentrer un peu dans les détails de l'API : structure, packages, fonctionnalités, exemples divers et tests. Pour finir, vous trouverez en fin d'article une partie téléchargements : les sources, la javadoc et un exemple de répertoire de ressources pour les tests. 2.0. Pour rentrer dans le vif du sujet ...2.1. Getting started2.1.1. Prérequis et téléchargementsPour pouvoir utiliser/compiler l'API vous devez avoir le JRE/JDK 5.0+ (celui de Sun de préférence : ici). Vous aurez aussi besoin des sources et du répertoire de ressources exemple. Pour finir, vous aurez aussi besoin d'un serveur local, au hasard Tomcat.
2.1.2. Installation et testsDécompressez les archives téléchargées dans le répertoire de votre choix. Elle contiennent deux projets Eclipse. Le premier est l'API (et ses tests), le second est le projet web contenant le répertoire de ressources. Testons un peu tout ca : Eclipse
Netbeans
Ant
 Adresse de déployement Si vous ne pouvez pas déployer ResourcesExamples à l'adresse http://localhost:8080/ResourcesExample : remplacez ses occurrences dans les fichiers : repository.xml, listeners-repository.xml et AbstractTest (projet Resources). Voila, si les tests se sont bien passés, on peut commencer :) Sinon, ca craint, on vous a dupé, faites une réclamation :(
2.1.3. "Hello Resources World"Dans ce petit exemple, on va charger un répertoire de ressources, quelques unes des ressources sur lesquelles il pointe et faire une recherche dans celles-ci. Le répertoire est situé à l'adresse : http://localhost:8080/ResourcesExample/repository.xml. Ce répertoire contient des pointeurs vers diverses ressources. Voici un extrait qui montre les trois ressources que l'on va utiliser pour l'exemple (la FAQ Java SE, la page de codes sources Java et le blog de la rubrique) :
  Fichier repository.xml <?xml version="1.0" encoding="UTF-8" standalone="yes"?> <resources:resource xmlns:resources="http://www.developpez.com/resources"> <id>repJava</id> <title>Répertoire de ressources Java</title> <!-- ... --> <element> <id>faqJavaSE</id> <title>FAQ Java SE</title> <url>http://java.developpez.com/faq/java</url> <authors/> <contentUrl>http://localhost:8080/ResourcesExample/faq-java.xml</contentUrl> <contentReader>com.developpez.resources.readers.FAQReader</contentReader> </element> <!-- ... --> <element> <id>sourcesJava</id> <title>Codes sources Java</title> <url>http://java.developpez.com/sources</url> <authors/> <contentUrl>http://localhost:8080/ResourcesExample/sources-java.xml</contentUrl> <contentReader>com.developpez.resources.readers.FAQReader</contentReader> </element> <!-- ... --> <element> <id>blogRubrique</id> <title>Blog de la rubrique Java</title> <url>http://blog.developpez.com/?blog=42</url> <contentUrl>http://blog.developpez.com/xmlsrv/rss2.php?blog=42</contentUrl> <contentReader>com.developpez.resources.readers.SyndicationReader</contentReader> </element> <!-- ... --> </resources:resource> Ce qu'il y a d'important de noter c'est que chacun de ces éléments a un identifiant, une URL de contenu et un lecteur de contenu. Par exemple, l'id de la FAQ Java est faqJavaSE, son url de contenu est http://localhost:8080/ResourcesExample/faq-java.xml
et son lecteur de contenu est un FAQReader.
Assez de blabla, lisons notre répertoire, chargeons ces trois ressources et faisons une recherche dans celles-ci. Voila notre Hello World :
HelloResourcesWorld
Qu'est ce qui s'est passé ?
Voila, voila, ... c'est (en gros) pas plus compliqué que ca. Passons aux détails maintenant :) 2.2. Architecture2.2.1. Vue d'ensemble Comme vous pouvez le voir ci-contre, la structure de l'API est relativement simple :
Commencons par regarder nos ressources (Resource, Category et Element) de plus près. 2.2.2. Les ressources Cliquez pour agrandir Pour schématiser, l'API représente simplement une arborescence de : Resource, Category et Element. Pour faire le parallèle avec l'API DOM ou tout est Node, dans notre cas tout est Element : on va donc commencer par faire le tour des éléments de ressources, puis des catégories de ressources, puis des ressources et pour finir des répertoires de ressources. Vous pouvez vous faire une idée en regardant le schéma ci-contre ou encore en regardant la javadoc (en fin d'article). 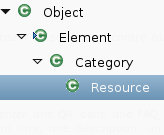 Elements Selon le contexte, un élément peut représenter une QR dans une FAQ, une entrée d'un flux RSS où comme on l'a déjà vu un "pointeur" vers une ressource. Ses attributs principaux sont un titre, une description, un contenu, une url, des dates de publication et mise à jour, et un ensemble d'auteurs (nom, éventuellement email et url). Les autres attributs concernent plutôt les "pointeurs de ressources" : une url de contenu, un lecteur de contenu et un délai de mis à jour. Comme vous pouvez le voir, ca casse pas trois pattes à un canard, mais ca nous permet de modéliser un ensemble de ressources très disparate. En fait, j'aurais bien repris des API comme DOM ou Rome pour ne pas réinventer la roue, mais l'une est "trop complexe" pour nos besoins et l'autre ne permet pas de gérer facilement les catégories de manière arborescente. Catégories 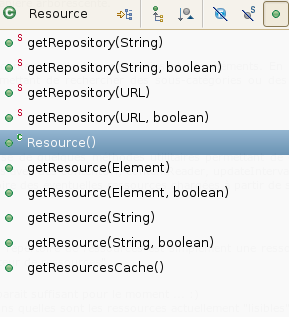 Une catégorie est simplement un Element contenant d'autres catégories et des éléments. En plus des méthodes d'accès à ces attributs, cette classe contient quelques méthodes utilitaires permettant de rechercher des sous-catégories ou des sous-éléments, de dénombrer le nombre de nouveaux éléments, etc. Ressources Une ressource est une catégorie qui dispose de quelques méthodes utilitaires permettant de charger certains de ses éléments (de type "pointeur de ressource", si si souvenez vous les éléments avec des contentUrl, contentReader, updateInterval ;).
Cette classe maintient aussi un cache mémoire des éventuelles ressources chargées à partir de ses "pointeurs". Répertoire Ne cherchez pas de classe Repository : un répertoire de ressources est simplement une ressource dont le reader est de type (DefaultReader) et dont l'ensemble des éléments sont de type "pointeur de ressources". Et je crois bien que c'est tout, mais ca me parait suffisant pour le moment ... :) Passons aux lecteurs de ressources et voyons quelles sont les ressources actuellement "lisibles" par notre API. 2.2.3. Les readers Cliquez pour agrandir Vous pouvez voir ci-contre la structure des lecteurs disponibles actuellement.
Ces premières implémentations nous permettent déjà de lire pas mal de types de ressources, mais, au pire, on peut encore en créer facilement si le besoin s'en fait sentir :) 2.2.4. Les writers Cliquez pour agrandir Avant de voir l'ensemble des tests unitaires créés pour l'occasion, faisons un tour de la contrepartie des readers : les writers. Comme je l'ai dit un peu plus haut, ces writers ont pour le moment deux utilités. Pour commencer, ce sont les outils utilisés pour le cache physique. Ce cache nous est indispensable, car il nous permet d'avoir accès aux ressources en "mode déconnecté" et d'avoir un accès rapide à ces données. En effet, la lecture d'une FAQ comme la FAQ java (qui dépasse les 10.000 lignes), sa transformation XSLT et sa lecture par JAXB ca peut être assez long. Quand je dis assez long, il faut relativiser (pour l'exemple donné, ca me donne en général : Full load ~ 2000ms, Disk load ~ 200ms, Memory load ~ 2ms). Enfin bref, pour de grosses ressources, qui plus est ne sont pas mise à jour tous les lundi, l'utilisation de ces caches me parrait utile. La seconde utilité de ces writers est de nous permettre de transformer certaines de nos ressources en flux de syndication. Par exemple, en attendant que ce soit intégré au Kit, on peut avoir des flux RSS pour nos FAQs, pages codes sources et pages livres. Passons maintenant aux tests unitaires. Si le HelloWorld vous a laissé sur votre faim (et que vous ne vous êtes pas encore endormi;) vous trouverez pas mal d'exemples d'utilisation ci dessous. 2.2.5. Les autres Cliquez pour agrandir Pour chacun de ces tests, l'integralité des caches sont vidés. ca permet aussi de se faire une idée des performances de la "bête". Sur ma machine l'ensemble des tests tournent en général en une vingtaine de secondes (sachant que le dernier en prend au moins une dizaine, sachant que c'est un thread qui tourne en attendant que la FAQ java se mette à jour au moins 5 fois, ce qu'elle fait toutes les secondes environ).
Voila pour les tests, c'est tout ce que nous avons pour le moment. D'autres choses sont à écrire/tester comme par exemple la synchronization de l'accès aux ressources ou au fichiers cache, le comportement en face de "mauvaises ressources", de ressources indisponibles, etc. Mais avant de peaufiner tout ca, il faut voir ce que vous pensez de tout ca, si ca vous intéresse, qui voudrait participer, tester, donner son avis sur le fait que le code est écrit dans un abominable franglais, etc. 3.0. Pour aller plus loin ...3.1. Téléchargements, liens et docs
3.2. ConclusionVoila, voila, toute remarque, commentaire, avis, conseil est le bienvenu. Et puis, si ca vous intéresse de continuer à bosser la dessus, surtout n'hésitez pas : tout le monde est le bienvenu :) |
